Labyrinthus
Published on Mar 22, 2024 by Kalitsune.
Original Challenge description 🇫🇷
En tant que courageux vaguemestre, vous êtes chargé de livrer des lettres et des messages essentiels entre différentes tranchées alliées. Cependant, les tranchées sont un réseau complexe à traverser mais il est vital que vous trouviez le chemin le plus sûr et le plus rapide pour accomplir votre mission. Votre objectif est, pour chacun des réseau de tranchées que nous vous montrerons, de trouver le bon itinéraire pour acheminer les lettres.
Challenge description 🇺🇸
As a brave vaguemestre, you're in charge of delivering vital letters and messages between different Allied trenches. However, the trenches are a complex network to traverse, and it's vital that you find the safest and quickest way to accomplish your mission. For each of the trench networks we'll show you, your aim is to find the right route for the letters.
Write up
Challenge inspection
This challenge is tagged as a programming challenge. As such, I’m expecting it to give us some kind of data in some way, probably a maze, that we have to process the quickest way possible (otherwise people would be tempted doing it by hand).
The good news is that we have a netcat address that we can check:
nc labyrinthus.nobrackets.fr 30731I’m imediately greeted by this:
Your task is to develop an algorithm for routing letters from S (start) to E (end) through a complex network of trenches, using an efficient route. For example, here's what you'll have to do:
Route map :
##################################
S ## ##
###### ## ################## ##
## ## ## ## ## ##
###### ## ## ## ###### ## ##
## ## ## ## ## ## ##
## ############## ## ## ## ##
## ## ## ## ##
###### ## ## ############## ##
## ## ## ## ##
## ############## ## ## ## ##
## ## ## E
##################################
Your map :
##################################
S:::::::## ##
######::## ################## ##
## ::## ## ## ## ##
######::## ## ## ###### ## ##
##::::::## ## ## ## ## ##
##::############## ## ## ## ##
##::::::## ## ## ##
######::## ## ############## ##
##:::::: ## ##::::::::::## ##
##::##############::## ##::## ##
##::::::::::::::::::## ##:::::::E
##################################
Now it's your turn!
Route map :
######################
S ## ##
## ###### ###### ##
## ## ## ##
############## ## ##
## ## ##
## ###### ## ## ##
## ## ## ## ##
###### ########## ##
## ## ##
## ########## ######
## ## ##
## ############## ##
## E
######################
Your map:
The good news is that this is indeed about solving mazes, the bad news is that it’s gonna take a little bit of work. But this is doable!
Extracting the maze from all this mess
The first step in solving this maze is actually getting the maze, I’m guessing that we only have a limited amount of time to solve it so there’s no way I’m doing it by hand. There’s a reason why I only play minecraft.. I’m too slow to do these kind of things.
Other solution: using socket (please don’t hurt me) uhm so you probably should not use socket it’s a big waste of time but I was too lazy do google the package name of the better alternatives so I ended up sticking with it.

I hope I won’t regret this later
anyway, joke aside, let’s start working on our program and try to print or maze:
import socket
# get the labyrinth patern
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(("labyrinthus.nobrackets.fr", 30731))
# we're only interested in the part comporting the actuall challenge, not in the tutorial part
labyrinth = s.recv(4096).decode().split("Now it's your turn!")[1]You’ll notice here that I’m not isolating the maze yet, only discarding the example. This is because I believe we’ll have to solve multiple mazes and that the server won’t send us a tutorial each time. As such, I’d like to do the actual maze extraction in a loop:
while True:
# isolate the challenge
labyrinth = labyrinth.split("Route map :")[1].split("Your map:")[0]
print(labyrinth)
# Solve the challenge
# Get the next challenge:
labyrinth = s.recv(4096).decode()and it seems to work!
##########################
S ## ##
########## ###### ######
## ## ## ##
## ## ## ## ###### ##
## ## ## ## ## ##
## ## ## ## ## ######
## ## ## ## ##
## ############## ## ##
## ## ## ## ##
## ## ###### ###### ##
## ## ##
###### ##################
## ## ## ##
## ## ## ## ## ## ##
## ## ## ## ## ##
## ## ## ########## ##
## ## ## E
##########################well… That’s the good news! The bad news is: it doesn’t solve the maze yet. Also, it just get stuck because it’s awaiting for the server to send something else but it never does so it’s just… stuck…
I hope this won’t become an issue later
Anyway, this part seems to be working, I’ll just add some code to remove the spaces at the beginning and at the end so it’s easier to work with it and we’ll start solving the maze!
# strip the spaces at the end and the begining of the string
labyrinth = "\n".join([i.strip() for i in labyrinth.splitlines() if i != ""])By doing this, we’re also removing the empty lines!
Doing the prepwork
To keep things simple, I’ll not be using a X and Y coordinate system, instead I’ll take advantage of the fact that this is a small rectangular grid and use the index of the letters in the string as coordinates.

To move, we just need to do simple some simple math depending on the movement we want to do:
UP --> -line_length (8 in this case)
DOWN --> +line_length (8 in this case)
LEFT --> -1
RIGHT --> +1I’m gonna start by parsing the maze to extract some useful information like the coordinates of the starting point and the exit point:
# parse the labyrinth
start_node, end_node, i = 0, 0, 0
for c in labyrinth:
match (c):
case "S": start_node = i
case "E": end_node = i
i +=1let’s also calculate the length of each lines so we don’t have to do this each time we want to move up and down
line_len = len(labyrinth.splitlines()[1])How does the A* algorithm works
Now that we’ve successfully extracted the relevant information from the maze, we can now proceed with solving it.
To navigate through this maze, I’ll be employing the A* algorithm (pronounced “A star”). This algorithm is widely used for pathfinding, so let’s take a moment to understand its workings before we dive into the implementation (note: you can also refer to this video).
A* functions by computing a cost, which is the sum of the distance from the starting node and the distance to the exit node:
cost = distance_start + distance_exit
Now, let’s illustrate this with an example: In the following image, each case depicts the distance from the starting node:
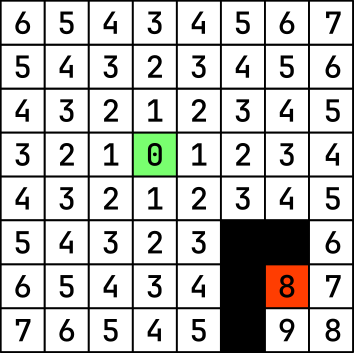
Similarly, this image represents the distance of each case from the exit node:
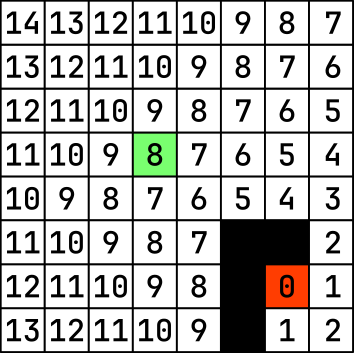
To determine the cost of each node, we simply sum the distances for each node:
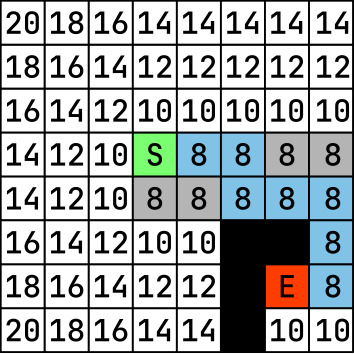
Then we navigate by computing the nodes’s neighbors cost that are next to the starting node with the lowest cost, then we start again with the neighbors of the neighbors nodes, etc… Until finding the exit node.
Implementing the A* algorithm to find the shortest path to the exit
In our case, we will try to find our way through an ascii maze so we’ll only do the processing if the neighbor is a space!
Here’s the python code:
this part goes at the beginning of the file:
from queue import PriorityQueue
# Define heuristic function (Manhattan distance)
# This returns the distance between the given node and the exit node.
def heuristic(node, goal, line_len):
node_x, node_y = divmod(node, line_len)
goal_x, goal_y = divmod(goal, line_len)
return abs(node_x - goal_x) + abs(node_y - goal_y)and this part goes in the loop:
# use priorituQueue to handle the node search more easily
pq = PriorityQueue()
pq.put((0, start_node)) # Priority queue with tuple (priority, node)
parents = {}
costs = {start_node: 0}
while not pq.empty():
current_cost, current_node = pq.get()
if current_node == end_node:
break # Goal reached, exit the loop :D
# note: [-1, 1, -line_len-1, line_len+1] is the list of allowed moves: ⬅➡⬆⬇
# note: it is important to add +1 to each moves because of the EOL char
for neighbor_delta in [-1, 1, -line_len-1, line_len+1]:
neighbor = current_node + neighbor_delta
# ensure that neighbor is within a reasonable range of numbers
# and check if the neighbor is a space or the exit node
if neighbor >= 0 and labyrinth[neighbor] != "\n"
and labyrinth[neighbor].isspace() or labyrinth[neighbor] == "E":
new_cost = costs[current_node] + 1
# there's no use in processing the same node two times
if neighbor not in costs or new_cost < costs[neighbor]:
costs[neighbor] = new_cost
priority = new_cost + heuristic(neighbor, end_node, line_len)
pq.put((priority, neighbor))
parents[neighbor] = current_nodeby the end of this script, we should have found the exit node and kept the shortest path this node in a binary tree hell:
'S'
/ \
35 28
/ \
36 29
/ \ \
37 30 38
/ \
31 39
/ \
47 55
/
'E'Transform our set of data into a unique path
To reconstruct the shortest path to the exit we’ll use this cool code snippet:
# Reconstruct the path
path = []
current_node = end_node
while current_node in parents:
path.append(current_node)
current_node = parents[current_node]
path.append(start_node)
path.reverse()it works by starting from the ending node and working its way up to the starting node at the top of the binary tree.
We then get a convenient array containing each nodes of the path we need to take in order to reach the exit node:
["S", 35, 36, 37, 31, 47, "E"]Visualizing the path
Now that we solved the maze, we still need to visualize the path on the ascii maze:
# Visualize the path
path_labyrinth = list(labyrinth)
for node in path:
if (path_labyrinth[node] not in ["S", "E"]):
path_labyrinth[node] = ':'
path_labyrinth = "".join(path_labyrinth)and.. We now should have a maze solver!
Let’s check how it looks:
######################
S:: ## :::::::::::: ##
##: ## :##########: ##
##: ## :## ## :::: ##
##: ## :## ## :######
##::::::## :::: ##
##################: ##
## ##: ##
## ##############: ##
## ## : ##
## ###### ######: ##
## ## ## : ##
## ## ###### ##: ##
## ## ##: ##
############## ##: ##
## ##:::E
######################
Well… It did solve it.. But we’re missing something there… I had not noticed that the path was two chars long in width… not ideal when using A*.
Fixing the issue
I tried various thing to fix the issue, the first one was fixing it by hand but it was taking too long and it didn’t work…

Doing it by hand doesn’t seems to be an option so we’ll have to work a bit to make a program that works.
I tried various thing while editing the # Visualize the path function but none of them worked. it was either skipping the corners (which looked cool but didn’t help) or filling entire rows (which didn’t help at all).
I ended up choosing to downscale the width of the maze during the solving phase and up scaling it back to it’s original form before submitting.
In order to do that I added this piece of code before parsing the maze:
# downscale the labyrinth so it's not a bother to process
# because of its big width
newLabyrinth = ""
imune = True
# Loop throught each lines of the maze
for l in labyrinth.splitlines():
# Loop throught each character of the current line
for c in l:
# only keep 1 character over 2
# but ensure that "E" and "S" are not discarded
if imune:
newLabyrinth += c
elif c in ["E", "S"]:
newLabyrinth = newLabyrinth[:-1] + c
# flip the imune value
imune = not imune
newLabyrinth += "\n"
labyrinth = newLabyrinthand another one after visualizing it to bring it back to its full scale:
labyrinth = ""
for l in path_labyrinth.splitlines():
labyrinth += " " # this adds the identation that we striped back
for c in l:
if c == "S":
labyrinth += "S:"
elif c == "E":
labyrinth += ":E"
else:
labyrinth += c+c
labyrinth += "\n"Done! it’s looking much better:
##########################
S:::::::::::## ## ##
##########::## ## ## ##
## ##::::::## ## ##
## ## ######::## ## ##
## ## ##::## ## ##
## ##########::## ## ##
## ## ##::## ## ##
## ## ## ##::###### ##
## ## ## ##::::::::::##
## ## ## ##########::##
## ## ## ##::::::##
## ## ###### ##::######
## ## ##::::::##
###### ## ##########::##
## ## :::E
##########################Submiting our answer
Now that we solved the maze we only need to submit it and it should be done!
# send the solution
print(labyrinth)
s.send(labyrinth.encode("utf-8"))
print("NEXT !")and editing the snippet of code getting the next maze so that it checks if we found a flag:
# read the next challenge
labyrinth = s.recv(4096).decode()
# Check if there's a flag in the challenge
if "NBCTF" in labyrinth:
print(labyrinth)
exit(0)and test our program! aannnd…
NEXT !
##########################################################################
S ## ## ## ## ## ##
## ## ## ###### ## ###### ############## ###### ########## ## ##
## ## ## ## ## ## ## ## ## ##
## ########## ## ###### ########## ## ###### ###### ## ##########
## ## ## ## ## ## ## ## ## ## ## ## ##
###### ############## ###### ## ###### ## ###### ## ## ###### ##
## ## ## ## ## ## ## ## ## ## ##
## ## ## ## ## ########## ###### ## ## ## ## ## ## ## ######
## ## ## ## ## ## ## ## ## ## ##
## ############################## ## ########## ########## ###### ##
## ## ## ## ## ## ## ## ## ## ##
## ## ## ## ###### ###### ## ########## ## ## ## ## ##########
## ## ## ## ## ## ## ## ## ##
########## ###### ###### ## ################## ###### ########## ##
## ## ## ## ## ## ## ##
## ## ########################## ## ## ## ## ## ###### ## ## ##
## ## ## ## ## ## ## ## ## ## ##
## ########################## ## ## #
Traceback (most recent call last):
File "/home/fanny/Documents/NBCTF/programmmation/labyrinth.py", line 71, in <module>
if neighbor >= 0 and labyrinth[neighbor] != "\n"
~~~~~~~~~^^^^^^^^^^
IndexError: string index out of rangeFixing the issue (again)
Okay so this is problematic but fixable, I guess that’s what you get for using socket. This could have been avoided..
Quote: me earlier
I hope I won’t regret this later
I hope this won’t become an issue later
Well.. what’s done is done, let’s try and fix that.
I tried augmenting the buffer size of the recv function, it helped but at one point it stopped actually changing. I also tried making looping recv function that received until the received packet was empty (meaning that the server had stopped). It didn’t work either (because the recv function is blocking remember) ![[python socket problem.png]] I heard of a way to make it non blocking but I wasn’t able to make it work. I ended up finding something that worked at the price of a slower runtime:
s.settimeout(0.2)I then made this function:
def recv_all(s):
received_data = b""
try:
while True:
chunk = s.recv(4096)
if not chunk:
break # No more data to receive
received_data += chunk
except socket.timeout:
# Handle timeout (no data received within the specified time)
pass
return received_dataand replaced every s.recv(4096) by recv_all(s). and… it worked!
Final program
before the grand finale, let’s print the full program in one code block so that you can use it:
from queue import PriorityQueue
import socket
def recv_all(s):
received_data = b""
try:
while True:
chunk = s.recv(4096)
if not chunk:
break # No more data to receive
received_data += chunk
except socket.timeout:
# Handle timeout (no data received within the specified time)
pass
return received_data
# Define heuristic function (Manhattan distance)
def heuristic(node, goal, line_len):
node_x, node_y = divmod(node, line_len)
goal_x, goal_y = divmod(goal, line_len)
return abs(node_x - goal_x) + abs(node_y - goal_y)
# get the labyrinth patern
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.settimeout(0.2)
s.connect(("labyrinthus.nobrackets.fr", 30731))
labyrinth = recv_all(s).decode().split("C'est à vous de jouer !")[1]
while True:
# isolate the challenge
labyrinth = labyrinth.split("Plan du parcours :")[1].split("Votre plan :")[0]
print(labyrinth)
# strip the spaces at the end and the begining of the string
labyrinth = "\n".join([i.strip() for i in labyrinth.splitlines() if i != ""])
# downscale the labyrinth so it's not a bother to process because of its big width
newLabyrinth = ""
imune = True
for l in labyrinth.splitlines():
for c in l:
if imune:
newLabyrinth += c
elif c in ["E", "S"]:
newLabyrinth = newLabyrinth[:-1] + c
imune = not imune
newLabyrinth += "\n"
labyrinth = newLabyrinth
line_len = len(labyrinth.splitlines()[1])
# parse the labyrinth
start_node, end_node, i = 0, 0, 0
for c in labyrinth:
match (c):
case "S": start_node = i
case "E": end_node = i
i +=1
# use priorituQueue to handle the node search more easily
pq = PriorityQueue()
pq.put((0, start_node)) # Priority queue with tuple (priority, node)
parents = {}
costs = {start_node: 0}
while not pq.empty():
current_cost, current_node = pq.get()
if current_node == end_node:
break # Goal reached, exit the loop
for neighbor_delta in [-1, 1, -line_len-1, line_len+1]:
neighbor = current_node + neighbor_delta
# ensure that neighbor is within a reasonable range of numbers and check if the neighbor is a space
if neighbor >= 0 and labyrinth[neighbor] != "\n"
and labyrinth[neighbor].isspace() or labyrinth[neighbor] == "E":
new_cost = costs[current_node] + 1
if neighbor not in costs or new_cost < costs[neighbor]:
costs[neighbor] = new_cost
priority = new_cost + heuristic(neighbor, end_node, line_len)
pq.put((priority, neighbor))
parents[neighbor] = current_node
# Reconstruct the path
path = []
current_node = end_node
while current_node in parents:
path.append(current_node)
current_node = parents[current_node]
path.append(start_node)
path.reverse()
# Visualize the path
path_labyrinth = list(labyrinth)
for node in path:
if (path_labyrinth[node] not in ["S", "E"]):
path_labyrinth[node] = ':'
path_labyrinth = "".join(path_labyrinth)
# double the width because we halved it at the begining
labyrinth = ""
for l in path_labyrinth.splitlines():
labyrinth += " "
for c in l:
if c == "S":
labyrinth += "S:"
elif c == "E":
labyrinth += ":E"
else:
labyrinth += c+c
labyrinth += "\n"
# send the solution
print(labyrinth)
s.send(labyrinth.encode("utf-8"))
print("NEXT !")
# read the next challenge
labyrinth = recv_all(s).decode()
# Check if there's a flag in the challenge
if "NBCTF" in labyrinth:
print(labyrinth)
exit(0)
and enjoy our sweet victory by getting:
Congratulations, you completed your mission! As a reward : NBCTF{V0S_LeTtres_0NT_81EN_ETe_tr4NsM1SES}conclusion: never use sockets. ever.
oh! what? puzzle.nobrackets.fr?
# create a socket connection with the server
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(("puzzle.nobrackets.fr", 30338))